Hiperhálózat tervez az embernél is hatékonyabban mesterséges intelligencia rendszereket

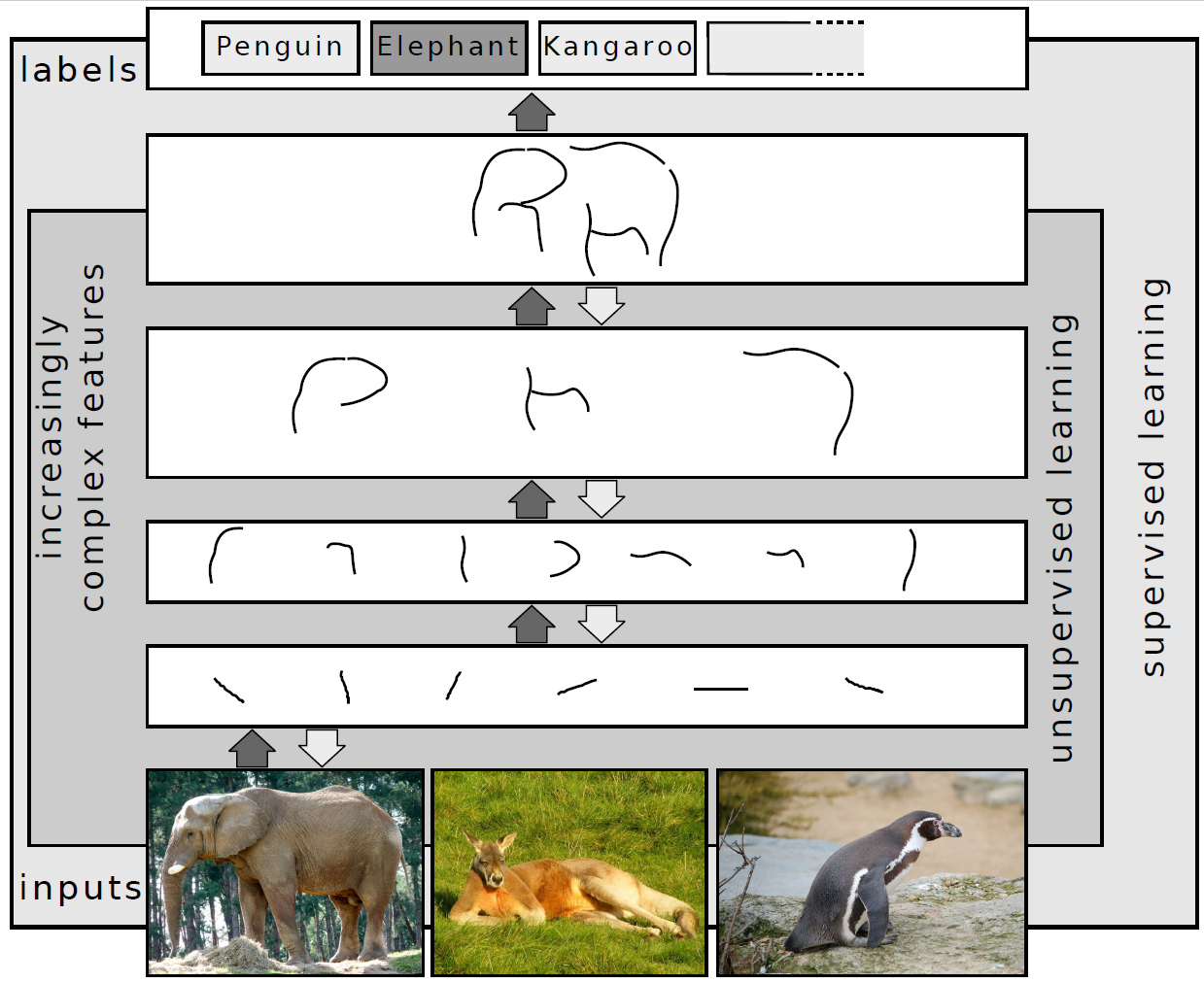
Az úgynevezett gráf hiperhálózatot 2018-ban hozták létre a Torontói Egyetem kutatói azzal a céllal, hogy lerövidítsék a mesterséges intelligencia algoritmusok hosszas betanítási folyamatát, amihez az ideális út a megfelelő struktúra előretervezése automatikus módon. Ahogy a kutatók a tanulmányukban írják: erre már korábban is létezett egy módszer, a NAS (neural architecture search, neurális hálózati keresés), ami önállóan rátalál az adott feladatot legjobban megoldó neurális háló topológiájára, vagyis le tudja írni a legideálisabb elrendezését egy hálózat csomópontjai közötti kapcsolatoknak.
A NAS-el tervezett mélytanulási hálók legalább olyan jól, ha nem jobban, teljesítenek, mint a kézműves munkával konfigurált modellek, amelyeknek előállítása függ a szakértő által ismert architektúrák számától is, ami valamivel behatároltabb lehetőségeket jelent, mint az automatizált módszer, ezenkívül rengeteg időt emészthet fel, hogy egy valóban hatékony eredmény születhessen.
A NAS használata csökkentheti a tervezésére szánt időt, de mégsem a leggazdaságosabb módszer, mivel a kereső rengeteg komplex elrendezést elemez a munkája során, ez pedig nagy számítási kapacitást igényel. A probléma megoldására már születtek a NAS-nek fejlettebb változatai is, például a Hatékony Neurális Hálózati Kereső, ami a GPU használatot töredékére, napok munkáját pedig néhány órára redukálja, de, mivel az eszköz csak bemutatja az ideális jelöltet, annak valós életbeli tesztelése során derül csak ki, hogy valóban megfelelően működik-e a modell.
A gráf hiperhálózat a drága és még mindig időigényes NAS-nak a továbbgondolásából jött létre: a hálózat a kezdeti súlyozást automatikusan végzi el és modellezi az adott architektúra topológiáját, ezzel az algoritmus leendő teljesítményét megbízhatóbban tudja előrejelezni. A rendszer, amely nevéhez híven grafikonon jeleníti meg a neurális hálózat felépítését, teljesítmény alapján osztályozza a jelölteket, majd ezeket a tudósok egyenként tesztelik egy-egy feladaton. A kutatások során az eljárás tízszer olyan gyorsnak bizonyult, mint más keresési módszerek.
Azonban a gráf hiperhálózatot is lehet még fejleszteni és gyorsabbá tenni, ezt bizonyítja az amerikai Guelph Egyetem kutatójának és munkatársainak legújabb találmánya, a GHN-2. Ez az új hiperhálózat nem teljesen követi az elődje működési elvét, az ideális algoritmus jelöltek osztályozása helyett a létrehozni kívánt hálózat paramétereinek kiválasztását, vagyis inkább a megfelelő paraméterek előrejelezését végzi, méghozzá a másodperc töredéke alatt. Ahhoz, hogy erre képes legyen, a rendszernek először meg kell tanulnia a bonyolult mélytanulási hálózatok általános felépítésének sajátosságait, majd ebből következtet a meghatározott feladat kivitelezéséhez legjobban illő struktúra alkotórészeinek értékeiről. A GHN-2 alkalmazása elméletben lerövidítheti vagy akár feleslegessé is teheti a hosszas, energiaigényes betanítási folyamatot, ami a mesterséges intelligencia rendszerek fejlesztésének egyik negatív velejárója.

Ahhoz, hogy a mára már mindenhol jelenlévő (a keresőkben, a telefonokon, a fordítóprogramokban, a képszerkesztőkben stb) mélytanulási mesterséges intelligencia rendszerek hiba nélkül vagy a lehető legkevesebb tévesztéssel végezzék a munkájukat, nagy mennyiségű adat betáplálásával kell gyakorlatoztatni őket, ez akár sok milliónyi, milliárdnyi szó, szöveg vagy kép beolvasását és ezután sokáig tartó próbálkozáson, majd a hibák kijavításán alapuló tanulási folyamatot jelent. A BERT természetes nyelvi feldolgozási modell egyik megalkotójának, Kate Saenkónak elmondása szerint a rendszer 3,3 milliárd angol nyelvű szót ismer, ezt az adatbázist a tanulás alatt 40 alkalommal ismételte át. A Massachusetts Amherst Egyetem kutatói kiszámolták, hogy ez megközelítőleg annyi szén-dioxid kibocsátással járt, mint egy New York-San Francisco közti repülőút oda-vissza. A Techtarget számításai szerint egy másik nyelvi modell, a MegatronML betanítási munkája 27 648 kWh energiába került.
A gyakorlási idő lerövidítése tehát fontos eleme lehet a jövőbeli mélytanulási MI hálózatok működtetésének, a GHN-2 pedig potenciálisan nagy segítséget nyújthat ebben. A mesterséges intelligencia hálózatot tervező mesterséges intelligencia hálózat hatékonysága, az általa ajánlott algoritmusok teljesítménye felveszi a versenyt a hosszabb tréningen átesett rendszerekével a vizsgálatok szerint, de azért a tanítási idő teljes kiiktatására még nincs lehetőség ezzel a módszerrel sem. A hiperhálózat azonban munkája során pontosan megtanulja a neurális hálózatok felépítésének sajátosságait, így sokkal közelebbi betekintést nyújthat a komplex rendszerek működésének rejtelmeibe, ami később segíthet a még hatékonyabb hálózatok tervezésében.
(Singularity Hub Fotó: Wikimedia Commons, Pixabay/Samdraft, Getty Images/DKosig)
Itt állíthatod be, hogy a Rakéta az elsők között legyen a Google keresőben

