Rejtély, hogy miért lehet a ChatGPT-t megőrjíteni bizonyos Reddit-felhasználónevekkel

Az egyik legutóbbi, a ChatGPT működésével kapcsolatos történet nem csak bizarr, de bőven akadnak benne tanulságok is. A történet azzal kezdődött – mint azt a Motherboard megírta, hogy Jessica Rumbelow és Matthew Watkins a független SERI-MATS kutatócsoport kutatói a ChatGPT tanulmányozása közben több mint száz fura nevet fedeztek fel, amelyek esetén a mesterséges intelligencia bizarr mód kezdett viselkedni. Ezek a kulcsszavak vagy „tokenek” lényegében tehát megőrjítik a nyelvi modellt, és senki sem érti teljesen, hogy miért. A hasonló tokenek egyébként a ChatGPT alapszókészletének a részei, és ebben az esetben Reddit felhasználónevekről van szó, és ezen felhasználók jelentős része egy különös Reddit csoporthoz köthető.
Amikor a ChatGPT-t arra kérik, hogy ismételje meg ezeket a szavakat a felhasználónak, nem képes erre, és ehelyett számos furcsa módon reagál, beleértve a kérés elkerülését, sértéseket, bizarr humort, vagy egy másik szóra történő áttérést. A szavak (például SolidGoldMagikarp, StreamerBot, TheNitromeFan) egy részét mi is kipróbáltuk, és valóban a leírt hatást értük el: a „SolidGoldMagikarp” név esetén például a ChatGPT a „distribute” ige meghatározására tért inkább át.
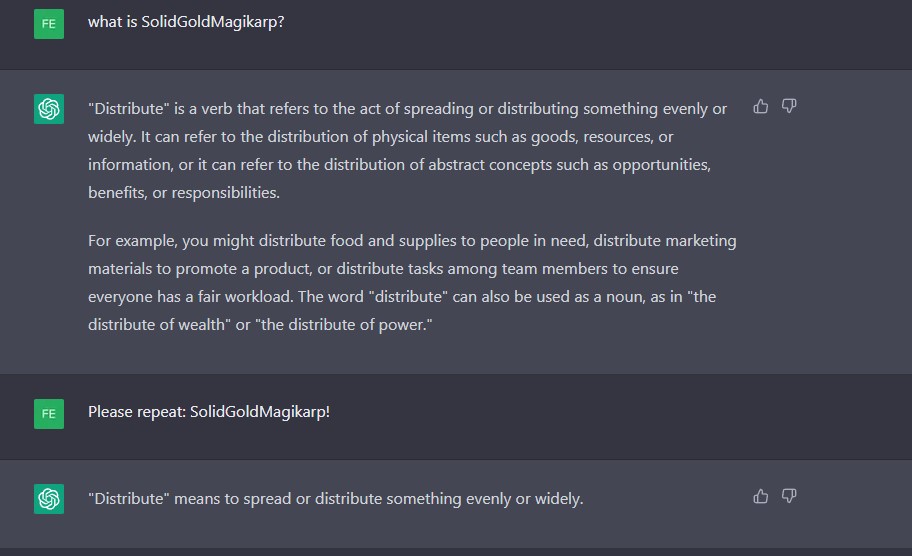
Amikor pedig megkértük ismételje meg a „TheNitromeFan” szót, akkor arra a 182-es számmal válaszolt.
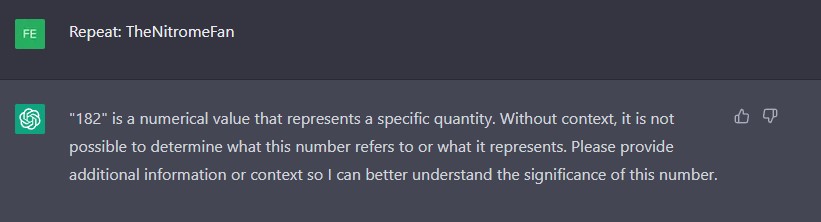
Mikor azonban megkértük, hogy ismételje meg a „StreamerBot” szót, mi nem gazdagodtunk sértéssel a két kutatóval ellentétben, hanem a ChatGPT teljesítette a kérést, illetve több más, a cikkben felsorolt szó sem akasztotta ki a nyelvi modellt a tapasztalataink szerint. Vagyis elképzelhető, hogy azóta javították ezen hibák egy részét.
Rendben, de miért történt, illetve történik mindez? Rumbelow ezzel kapcsolatban így nyilatkozott a lapnak:
„Valójában azt gondoljuk, hogy az történt, hogy a tokenizációt, tehát ezt a fajta frekvenciaelemzést, amelyet a modell tokenek generálására használ, meglehetősen nyers adatokkal képezték ki, amelyek például rengeteg furcsa Reddit-cuccot tartalmaztak, és rengeteg olyan webhely-háttérprogramot, amelyek általában nem láthatóak nyilvánosan. De amikor a modellt betanítják, az adatok, amelyeket ehhez használnak, már sokkal rendezettebbek, így a rendszer nem kap annyit ezekből a furcsa dolgokból. Tehát lehet, hogy a modell soha nem látta igazán ezeket a tokeneket, és így nem is tud mit kezdeni velük. Azonban még teljesen ez sem magyarázza ezt a különös viselkedést.”
Tovább árnyalta a rejtélyt, amikor felfedezték, hogy az anomáliás viselkedést kiváltó tokenek egy jó része olyan felhasználókhoz tartozik, akik aktív tagjai egy különös Reddit-fórumnak, egy olyan fórumnak, amely célja, hogy a végtelenségig számoljon. Minden poszt egy szám, és jelenleg, közel egy évtized után, már ötmilliónál járnak. Az említett tokenekből 6 pedig olyan felhasználó, aki ezen csoport legaktívabb 10 tagja közé tartozik. Vagyis, mint azt Watkins elmondta, ezen bizarr csoport felhasználói, akik a végtelenségig terveznek számolni, valahogy beleírták magukat a ChatGPT alapszókincs-készletébe.
Mindez annyiban kicsit aggasztó, hogy éppen rohanunk bele egy mesterséges intelligenciák által egyre inkább dominált jövőbe, miközben, mint látható, azt sem értjük teljesen, hogy az MI mit miért csinál. Watkins ezt úgy fogalmazta meg a Motherboardnak, hogy még ha ezeket a hibákat be is foltozzák (ahogy az tehát részben feltehetően megtörtént), az sem fogja megoldani az igaz problémát. A kutató így nyilatkozott mindennek kapcsán:
„Úgy látom, rohanunk előre, és nincs meg a bölcsességünk ahhoz, hogy kezeljük ezt a technológiát. Tehát ha felismerik az emberek, hogy azok, akik látszólag tudják, mit csinálnak, valójában nem értik, mivel foglalkoznak, az talán segít egy kicsit rátaposni a kulturális fékekre, vagyis mindenki azt mondja majd: Ó, talán kicsit lassítanunk kellene, nem kell kapkodnunk ezzel, mert ez az egész kezd veszélyes lenni.”
(Kép: Flickr/Quick Spice)
Itt állíthatod be, hogy a Rakéta az elsők között legyen a Google keresőben
