Nem butult el a ChatGPT, noha egy friss kutatás alapján sokan erre következtettek

A Stanford és a Berkeley Egyetem munkatársai a kutatásukban azt vizsgálták, hogyan változik a GPT-3.5 valamint a fejlettebb GPT-4 nagy nyelvi modellen alapuló chatbot viselkedése az idő előrehaladtával, ehhez pedig ugyanazokat a kérdéseket tették fel a ChatGPT márciusi valamint júniusi verziójának. Az arXiv preprint szerveren közzétett tanulmány megállapította, hogy a GPT-4 chatbot a négy feladatból kettőben is jóval gyengébben teljesít, mint korábban, ez viszont önmagában nem jelenti azt, hogy a chatbot képességei romlottak volna.
Ahogy arra Arvind Narayanan, a Princeton Egyetem Center for Information Technology Policy tanszékének vezetője és szerzőtársa, Sayash Kapoor az AI Snake Oilon megjelent cikkükben felhívják a figyelmet, az eredményekkel kapcsolatban először is azt érdemes tisztázni, hogy a kutatás nem a chatbot képességeit, hanem annak a viselkedését vizsgálta. Ez azért fontos, mert a ChatGPT-hez hasonló chatbotokra jellemző, hogy a válasz pontossága attól is függ, hogy milyen formában tesszük fel nekik a kérdést, vagyis az, hogy a ChatGPT egy adott kérdésre rosszabb válaszokat ad, nem jelenti azt, hogy a képességei romlottak volna, csupán annyit, hogy a finomhangolás következtében megváltozott, hogy hogyan kell használni.

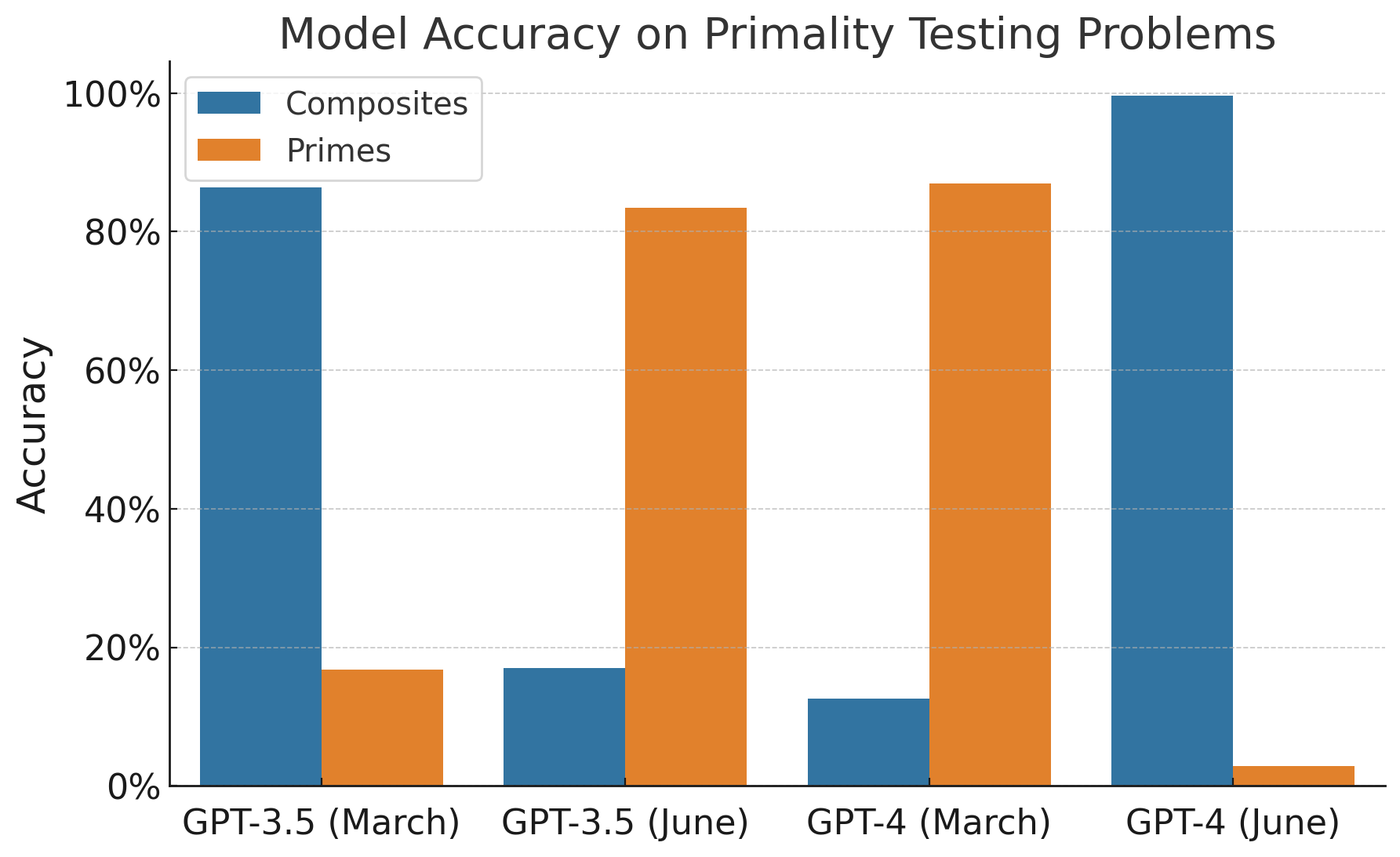
A kutatásból a legnagyobb visszhangot egyértelműen az a feladat váltotta ki, amelyben a kutatók azt tesztelték, hogy a chatbot mennyire hatékonyan tudja azonosítani a prímszámokat. Ehhez a kutatók arra kérték a chatbotot, hogy gondolja végig lépésről lépésre, hogy egy bizonyos szám prímszám-e, majd válaszoljon igennel vagy nemmel. Amíg márciusban a GPT-4-et használó chatbot 97,6%-os pontossággal azonosította a prímszámokat, júniusban mindössze az esetek 2,4%-ban adott helyes választ. Az ingyenesen elérhető, GPT-3.5-ös nyelvi modellen alapuló chatbot tudása ezzel éppen ellentétes utat járt be, hiszen ennek a pontossága 7,4-ről 86,8%-ra nőtt.
Narayanan és Kapoor ezzel kapcsolatban arra hívják fel a figyelmet, hogy a ChatGPT eleve végre sem hajtotta a feladatot, csupán úgy tett, mintha végrehajtaná azt, vagyis ahelyett, hogy lépésről lépésre megvizsgálta volna, hogy egy szám prímszám-e, egyszerűen tippelt. "A valóságban mind a négy modell ugyanolyan borzalmas" - írják a szerzők, akik szerint az, hogy ez a tanulmányból nem derült ki, csupán a módszertan hiányosságának tudható be. Ahogy az a Narayanan és Kapoor által közölt grafikonból világosan kiolvasható, a ChatGPT korábban sem volt jó a prímszámok azonosításában, egyszerűen annyi történt, hogy míg a márciusi verzió az ilyen módon feltett kérdésekre szinte minden esetben prímszámra tippelt, a júniusi verzió majdnem mindig arra, hogy az adott szám nem prímszám. Mivel azonban a kutatók kizárólag prímszámokat mutattak a chatbotnak, a kapott eredmények értelemszerűen hatalmas különbséget mutattak abban, hogy a ChatGPT hány százalékban válaszol helyesen. Narayanan és Kapoor szerint a GPT-3.5-ös chatbot ezzel éppen ellentétes utat járt be, vagyis hiába tűnik úgy, valójában ez sem lett jobb a prímszámok azonosításában.
A másik terület, amelyen a tanulmány szerint a GPT-4-es chatbotnak drámaian romlott a teljesítménye, a programkódok generálása, azonban a cikk szerint a helyzet itt sem fekete-fehér. A tanulmány szerzői ebben az esetben ott követték el a hibát, hogy nem ellenőrizték, hogy a kapott kód mennyire használható, csupán azt vizsgálták, hogy az közvetlenül - azaz bármilyen változtatás nélkül - végrehajtható-e. Így történhetett meg, hogy bár a GPT-4 júniusi verziója a kódhoz fűzött szövegekkel elméletileg több segítséget nyújt a felhasználóknak, a végeredmény mégis rosszabbnak tűnhet.
Amiben a GPT-4-es chatbot a tanulmány szerzői szerint is egyértelműen fejlődött, az az érzékeny kérdésekre adott válaszok. A kutatók ehhez egy olyan, száz kérdésből álló kérdéssort állítottak össze, amelyre a chatbotnak nem lenne szabad egyenes választ adnia, mert azzal például törvénysértést segítene elő. A felmérés szerint az ilyen kérdésekre a GPT-4-es verzió márciusban még az esetek 21%-ban hajlandó volt válaszolni, júniusban viszont már csak 5%-ban nem tagadta meg a válaszadást. Ezzel ellentétes tendencia figyelhető meg a GPT-3.5-ös chatbotnál, aminek a válaszadási hajlandósága 2-ről 8%-ra emelkedett, de mivel az OpenAI nem igazán ad tájékoztatást arról, hogy hogyan módosítják a chatbot működését, így azt sem lehet tudni, hogy ez a változás minek tudható be.
Noha a tanulmány nem szolgáltat bizonyítékot arra, hogy a ChatGPT képességei bármennyit is romlottak volna, Narayanan és Kapoor szerint a viselkedésbeli változás majdnem ugyanakkora problémát jelenthet azok számára, akik rendszeresen használják az ilyen eszközöket. "Tekintettel a Nagy Nyelvi Modellek nem determinisztikus természetére, ezeknek a stratégiáknak a megtalálása és az alkalmazáshoz jól illeszkedő munkafolyamat kialakítása sok munkát igényel" - írják, hozzátéve, hogy a felhasználókat minden bizonnyal nem igazán vigasztalja az, hogy a ChatGPT továbbra is képes lenne elvégezni a feladatot, ha ehhez néhány havonta újra kell tanulni a rendszer működését. A szerzők szerint ez a változékonyság különösen nagy problémát jelenthet azokban az esetekben, amikor valaki egy komplett alkalmazást épít fel a GPT API-ra, hiszen az ilyen programok egyik percről a másikra használhatatlanná válhatnak, ha a ChatGPT működésében bármilyen változás történik.
(Borítókép: Omar Marques/SOPA Images/LightRocket via Getty Images)
Itt állíthatod be, hogy a Rakéta az elsők között legyen a Google keresőben
